组会分享TIMER-XL
TIMER-XL: LONG-CONTEXT TRANSFORMERS FOR UNIFIED TIME SERIES FORECASTING
长上下文Transformer 统一的时间序列预测。
从题目入手:
- 长文本:NLP领域的Transformer学习成千上万的token间依赖,传统只能学几百个token。
- 统一预测:做出改变:1维的token 预测 下一个token 改成→ 2维的(多变量)。
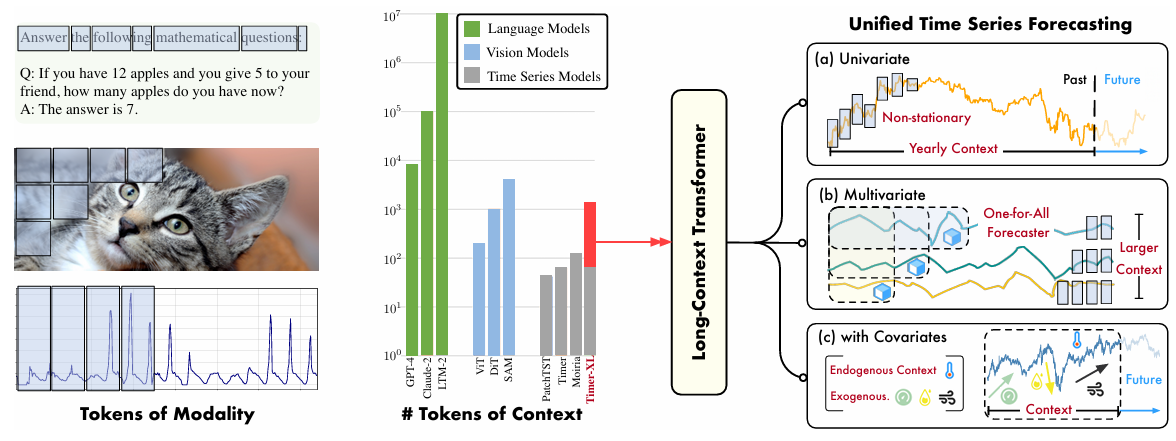
图中介绍了何为token,以及不同模态(语言模型、视觉模型、时序模型)Transformer处理的上下文长度。
总结本文做了两个工作:
1.使用了NLP领域的Transformer应用到时序领域来,能处理更长的时间依赖;
2.在Transformer中包含了单变量、多变量(多目标变量/多协变量+一目标变量)。
模型:使用decoder-only的Transformer,利用不同长度的上下文来捕捉因果依赖关系。
因果(Causality)通常指的是模型在处理序列数据时,只能使用当前时间点之前的信息,而不能“看到”未来的信息。
通过“自注意力”和“因果掩码”实现。
使用因果掩码(Causal Masking): 在计算**注意力权重(Attention Weights)**时,对未来的时间步置零,使得模型在计算第 ttt 个时间步的预测时,只能看到时间步 ≤t\leq t≤t 的数据。
解码器架构(Decoder-Only Architecture): 采用自回归(Autoregressive) 方式进行预测,即模型逐步预测每个时间步的值,并将已预测的值输入到后续时间步的计算中,而不是一次性输出整个序列。
创新:1.提出了通用的TimeAttention机制;2.位置编码。
其中TimeAttention中提到了:Kronecker-based mask 和 RoPE 两个技术。
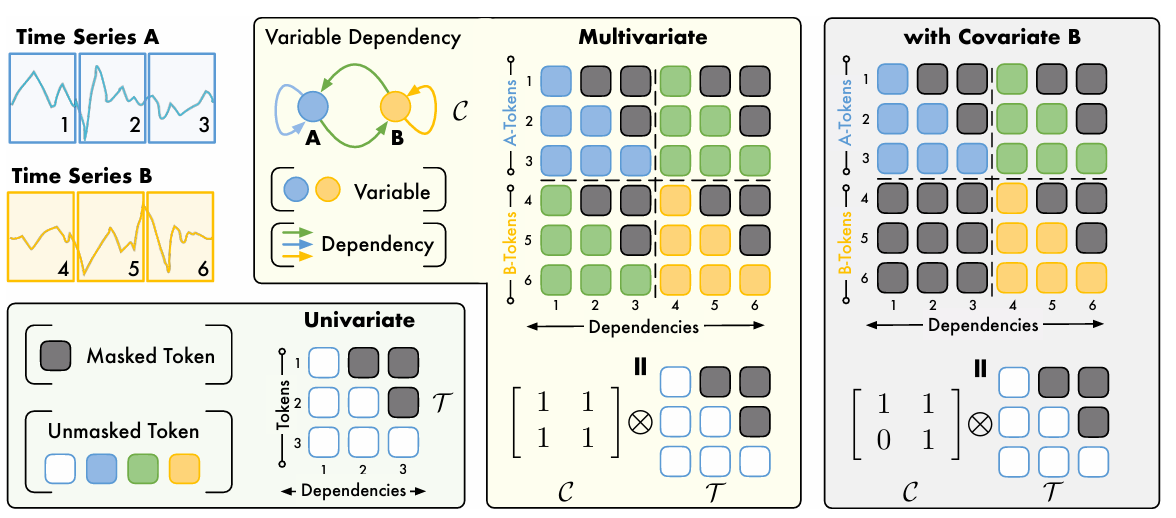
此为模型结构图。
1 | |
Kronecker 乘积 $ C⊗T $
变量依赖矩阵(时间因果) $C$ 与时间掩码 $T$ 通过 Kronecker 乘积,将变量间的依赖关系 (C) 和时间序列的因果结构 (T) 结合,形成一个完整的 注意力掩码(Attention Mask)。保证 Transformer 既能考虑时间因果性,又能捕获变量之间的相互影响。
RoPE 旋转位置编码:旨在为Transformer模型提供相对位置信息。
$RoPE(Q,K)=QR_θK^T$
其中,$R_{\theta}$ 是一个基于位置索引 $p$ 和一个预设的基数 $θ$ 生成的旋转矩阵。
==RoPE 在注意力计算时,利用旋转变换引入相对位置信息,而不是直接添加位置编码。==
可学习的标量参数(Scalars)
$Attention(Q,K,V)=softmax(\frac{S_1⋅QK^T}{S_2·\sqrt{d}})V$
在注意力机制中,每个注意力头(Attention Head)通常会处理不同的子空间信息。可以使用可学习的标量参数来调整不同变量的贡献。
TimeAttention 计算公式
$TimeAttention(H)=Softmax(\frac{Mask(C⊗T)+A}{\sqrt{d_k}})HW_v.$
$Mask()$ 的作用 $M_{i,j} = 1$ 该位置$=0$;$M_{i,j} = 0$ 该位置$=-∞$。相当于做了一步它和邻接矩阵相加,更改邻接矩阵的步骤,算是一个小优化。
$H$ 特征矩阵
$W_v$ 投影矩阵
$d_k = \frac{D}{head数量}$ 缩放因子(D是隐藏层维度)
实验部分
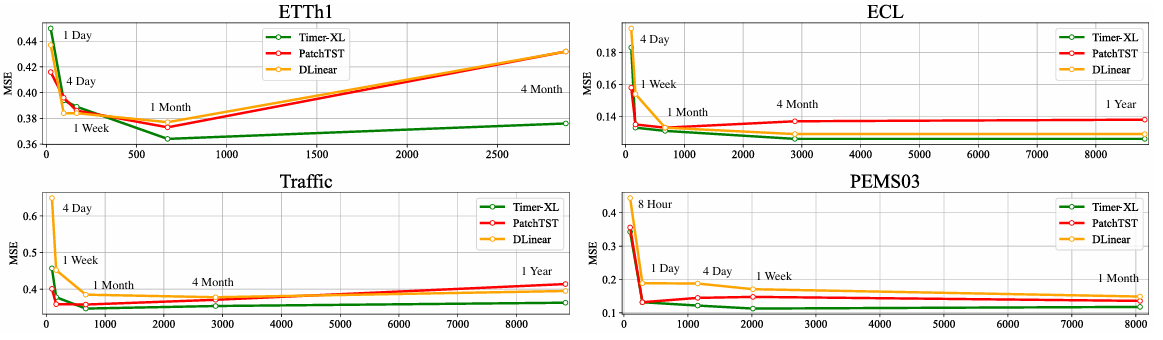
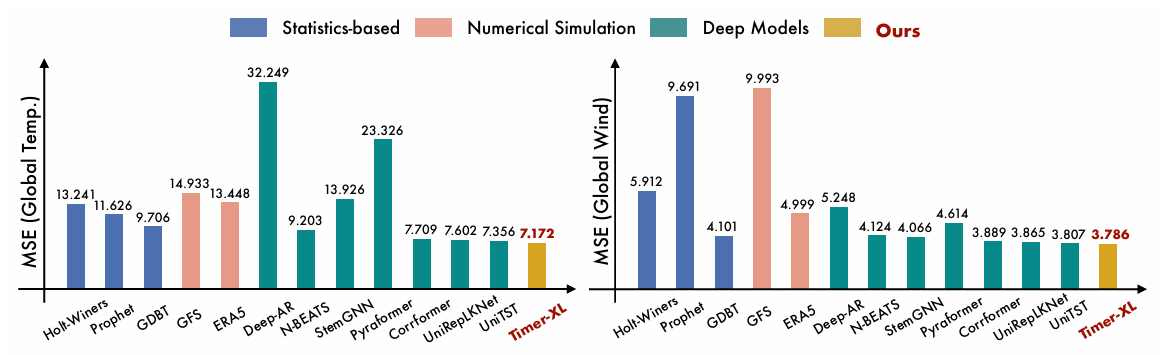
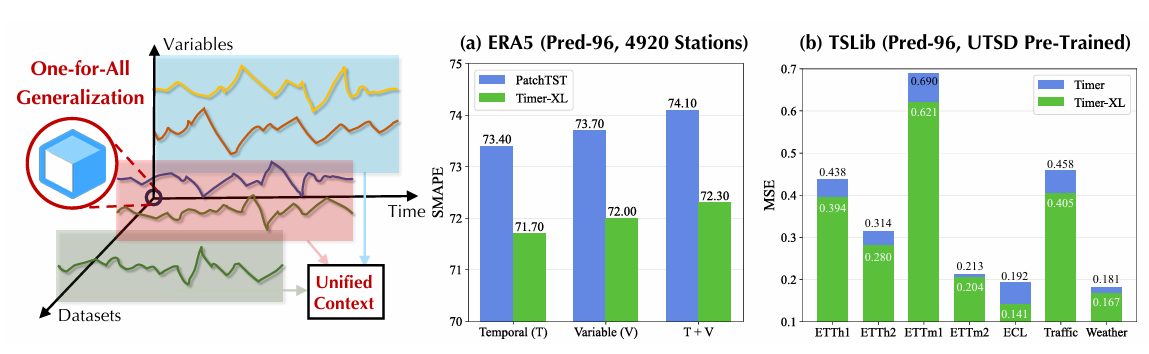
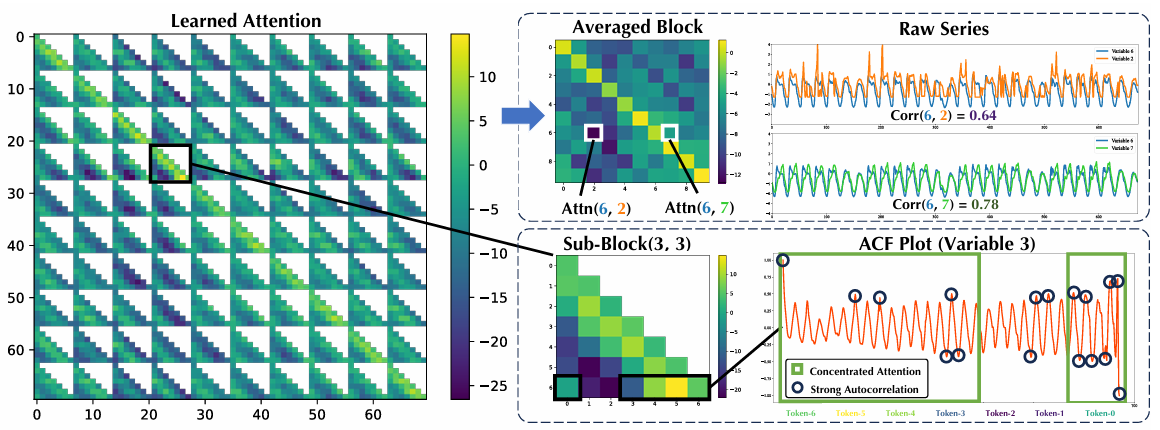
分别对:上下文长度、单变量预测、多变量预测、协变量预测、零样本做了对比实验。
又对:模型效率进行了实验。